
CUDA 프로그래밍 - 병렬 처리란? (2)
목차
- SIMD, 데이터 수준 병렬화
- 공유 메모리 시스템, 분산 메모리 시스템
- SIMT 구조의 특징
오늘은 지난 포스팅에 이어 병렬 처리에 대한 내용을 설명하고자 합니다. 병렬 처리의 개요, 동시성, 병렬성 프로그래밍, 병렬 처리 하드웨어에 관한 내용이 궁금하시면 이전 포스팅을 참고해 주세요.
CUDA 프로그래밍 - 병렬 처리란? (1)
CUDA 프로그래밍 - 병렬 처리란? (1) 목차 병렬 처리 개요 동시성 vs 병렬성 병렬 처리 하드웨어 분류 마치며 지난 포스팅에서 GPU(Graphic Processing Unit), GPGPU(General Purpose GPU)의 개념과 특징에 대해 알아
kudositdaily.tistory.com
SIMD, 데이터 수준 병렬화
이전 발행 글에서 플린의 병렬 처리 하드웨어 분류를 소개해 드렸습니다. 병렬 처리 하드웨어는 '데이터에 대해 한 번에 수행하는 명령어(instruction) 개수'와 '명령어 혹은 명령어들이 수행되는 데이터 개수'에 따라 SISD, MISD, SIMD, MIMD로 분류됩니다. 특히, 데이터 수준 병렬화(data-level parallelism)에 대해 다루기 위해 SIMD 구조를 이해하면 좋습니다.
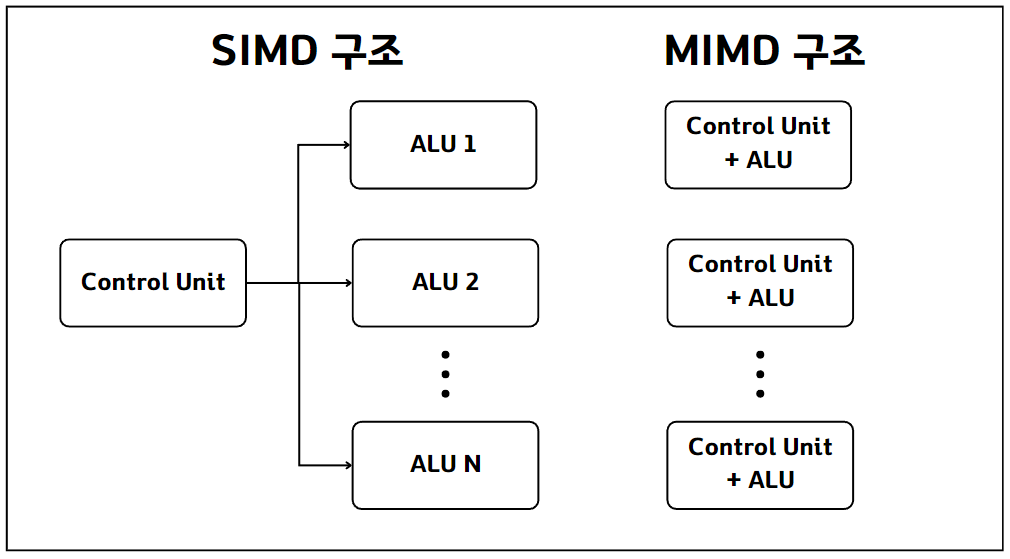
위 그림의 왼쪽 구조는 간단한 SIMD 구조를 보여줍니다. 그림의 ALU(Arithmetic Logic Unit)는 산술 논리 장치로 하나의 연산 유닛 또는 코어를 의미합니다. SIMD 구조에서는 하나의 제어 장치(control unit)가 N개의 ALU를 제어합니다. 즉, 동일한 제어 명령으로 여러 개의 코어를 제어하는 구조입니다.
SIMD의 동작 방식을 SISD와 비교해 보도록 하겠습니다. 아래의 예제는 두 벡터의 합을 구하는 코드입니다. SISD의 경우, 20번의 연산을 통해 각 원소의 합을 구합니다. 반면 SIMD는 여러 개의 연산 유닛을 활용하여 한 라운드에 여러 데이터를 처리할 수 있습니다.
// x, y 배열 합 구하기
for (int i=0; i < 20; i++) {
x[i] += y[i];
}
예를 들어, 네 개의 ALU를 가진 SIMD 하드웨어를 활용한다고 가정하겠습니다. SIMD 하드웨어는 한 라운드에 네 개의 데이터를 한 번에 처리할 수 있고, 총 다섯 번의 반복을 통해 20개의 데이터를 처리할 수 있습니다. 이처럼 동일한 연산을 동시에 여러 데이터에 적용하는 병렬 처리 기법을 데이터 수준 병렬화라고 합니다.
| Round | ALU1 | ALU2 | ALU3 | ALU4 |
| 1 | x[0] | x[1] | x[2] | x[3] |
| 2 | x[4] | x[5] | x[6] | x[7] |
| 3 | x[8] | x[9] | x[10] | x[11] |
| 4 | x[12] | x[13] | x[14] | x[15] |
| 5 | x[16] | x[17] | x[18] | x[19] |
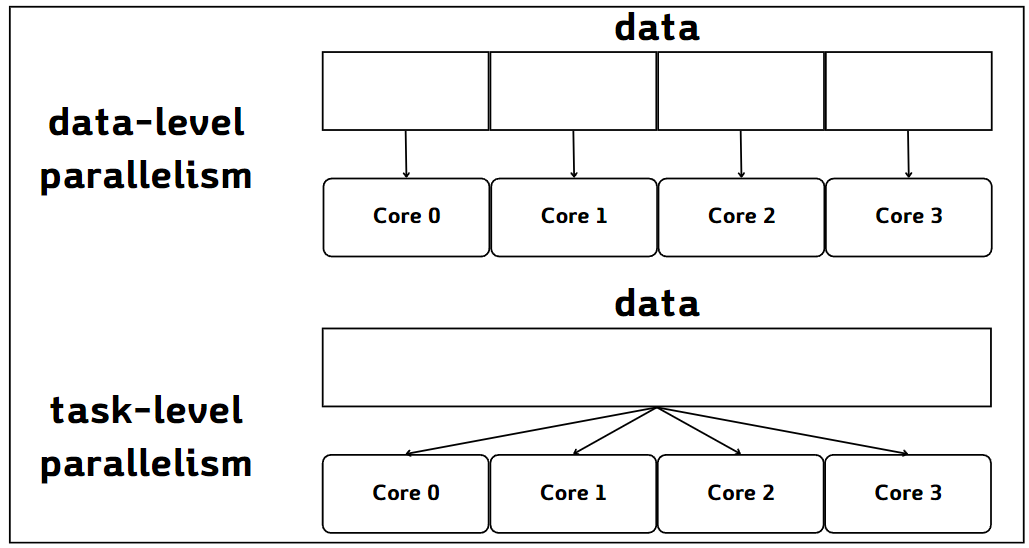
데이터 수준 병렬화와 비교되는 개념으로 태스크 수준 병렬화(task-level parallelism)가 있습니다. 데이터 수준 병렬화가 동일한 작업을 병렬적으로 수행하는 방법이라면 태스크 수준 병렬화는 서로 다른 작업들을 병렬적으로 수행하기 위한 방법입니다. 아래의 그림은 데이터 수준 병렬화와 태스크 수준 병렬화를 비교하는 그림입니다.
공유 메모리 시스템, 분산 메모리 시스템
병렬 처리 하드웨어의 또 다른 분류 기준은 연산 유닛들 사이의 메모리 공유 여부입니다. 이에 따라 병렬 처리 시스템은 공유 메모리 시스템(shared memory system)과 분산 메모리 시스템(distributed memory system)으로 구분됩니다.
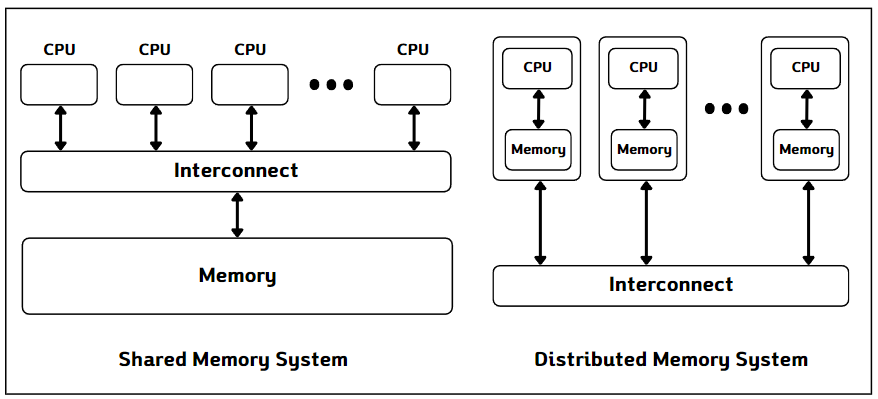
공유 메모리 시스템은 병렬 시스템 내 연산 유닛들이 하나의 메모리 공간을 공유하는 시스템입니다. 멀티코어 CPU에서 여러 개의 연산 코어가 메인 메모리를 공유하는 것이 대표적인 예시입니다. 공유 메모리 시스템에서는 여러 스레드가 같은 메모리 공간을 동시에 접근할 수 있기 때문에 접근 시 주의가 필요합니다. 따라서, 동시 접근 시, 문제를 예방하기 위해 작업 순서를 맞춰야 하는데, 이러한 과정을 동기화(synchronization)라고 합니다.
병렬 처리 시스템은 장치 내 연산 장치가 독립된 메모리 공간을 가지고, 명시적인 통신을 통해 정보를 교환하는 시스템을 말합니다. 여러 대의 컴퓨팅 노드를 연결한 컴퓨팅 클러스터가 대표적인 예시입니다. 분산 메모리 시스템에서는 네트워크 등을 통해 데이터를 주고받아야 합니다. 통신으로 데이터를 주고받을 경우, 통신 부하가 클 수 있습니다. 따라서, 효율적인 병렬 처리 알고리즘 설계를 위해 통신 부하를 줄이는 것이 중요합니다.
그렇다면 GPU는 어떤 병렬 처리 하드웨어 시스템일까요? 플린의 분류법에 따르면 SIMD 구조에 속하고, 데이터 수준 병렬 처리에 적합한 하드웨어입니다. 메모리 공유 방식에 따른 분류로는 공유 메모리 시스템에 속합니다. 하지만, GPU는 일반적으로 SIMD가 아닌 단일 명령-복수 스레드(Single Instruction-Multiple Thread) 구조로 정의됩니다. 이는 하나의 명령어가 여러 스레드에 명령을 내리는 구조를 의미합니다. 따라서, GPU는 SIMT 구조의 병렬 처리 하드웨어이며, 공유 메모리 시스템입니다.
SIMT 구조의 특징
GPU는 SIMT 구조의 병렬 처리 하드웨어입니다. SIMD와 구분되는 SIMT 구조의 특징은 다음과 같습니다.
1. 한 스레드 그룹 내 스레드들을 하나의 제어 장치로 제어한다.
SIMD와 유사하게 SIMT에서도 하나의 제어 장치가 코어 여러 개를 제어합니다. 하지만 SIMT가 제어하는 그룹의 논리적인 단위가 스레드라는 점에서 차이가 있습니다.
2. 각 스레드는 자신만의 제어 문맥을 가진다.
SIMT에서 스레드가 논리적 제어 단위라는 것은 각 스레드가 자신만의 제어 문맥을 갖는다는 의미입니다. SIMD의 경우, 하나의 제어 문맥으로 여러 데이터에 동일한 명령을 적용합니다. 따라서, 각 데이터에 서로 다른 연산 로직을 부여할 수 없습니다. 하지만 SIMT의 경우, 하나의 제어 장치가 여러 스레드를 제어하고, 서로 독립된 제어 문맥을 가질 수 있습니다.
3. 그룹 내 스레드들 사이의 분기가 허용된다.
SIMT에서 각 스레드가 독립된 제어 문맥을 가지기 때문에, 한 그룹 내 스레드 사이의 분기를 허용합니다. 한쪽 분기를 따르는 스레드들을 처리한 후, 다른 분기를 따르는 스레드들을 처리하는 방법으로 모든 스레드의 작업을 처리할 수 있습니다. 이 과정에서 성능 저하가 발생할 수 있지만, SIMD에 비해 프로그래밍 자유도를 높일 수 있다는 장점이 있습니다.
마치며
두 차례의 포스팅을 통해 병렬 처리의 개념에 대해 소개해 드렸습니다. 이어지는 다음 포스팅부터 CUDA에 대해 본격적으로 다뤄보도록 하겠습니다. 오늘 포스팅도 도움이 되셨기를 바랍니다. 고맙습니다.
Reference
1. CUDA 기반 GPU 병렬 처리 프로그래밍 - 기초부터 성능 최적화 전략까지
'Tech Insights' 카테고리의 다른 글
| CUDA 프로그래밍 - Hello CUDA! (Linux) (0) | 2024.03.02 |
|---|---|
| CUDA 프로그래밍 - Hello CUDA! (0) | 2024.03.02 |
| CUDA 프로그래밍 - 병렬 처리란? (1) (2) | 2024.02.24 |
| CUDA 프로그래밍 - GPGPU? GPU 프로그래밍 (0) | 2024.02.23 |
| 파이썬을 활용한 OpenAI Assistants API 기초 사용법 (0) | 2023.12.15 |



