
랭체인(LangChain), Streamlit을 활용한 실시간 텍스트 나누기
목차
- Streamlit을 통해 실시간 입력 화면 구성하기
- LangChain Text Splitters를 통한 텍스트 나누기
- 마치며
안녕하세요, 이번 포스팅에서는 랭체인에서 제공하는 텍스트 스플리터(Text Splitters) 기능에 대해 소개해드리고자 합니다. 언어 모델을 활용한 애플리케이션을 개발할 때, 다양한 형태의 텍스트를 언어 모델의 입력으로 전달하게 됩니다. 사용자가 전달하는 텍스트는 애플리케이션에 따라 다양한 형태의 포맷이 존재하고 텍스트의 크기 또한 천차만별입니다. 따라서, 효과적으로 언어 모델을 활용하기 위해 입력 텍스트를 적합하게 변환하는 작업이 필요합니다.
랭체인에서는 입력되는 텍스트를 청크로 분할하는 작업이나 다시 결합하는 작업, 필터링과 같은 텍스트 변환을 쉽게 수행할 수 있도록 여러 기능(Document transformers)을 제공합니다. 랭체인에서 제공하는 핵심 모듈에 대해 궁금하신분들은 LangChain - 초보자를 위한 완벽 가이드를 참고해주시기 바랍니다. 오늘은 그 중에서 입력된 텍스트를 청크로 분리해주는 텍스트 스플리터 대해 다룰 예정입니다. 텍스트 스플리터가 동작하는 방식은 크게 다음과 같이 나눌 수 있습니다. 사용자는 텍스트를 분리하는 과정에서 분리 방식이나 청크 사이즈 등을 설정할 수 있습니다.
- 텍스트를 작고 의미론적으로(Semantically) 유의미한 청크로 분리
- 분리된 청크를 특정 사이즈에 도달할 때까지 큰 청크로 결합
- 특정 사이즈에 도달하면 해당 조각을 독립적인 텍스트로 만들고, 조각 간의 맥락을 유지하기 위해 오버랩을 통해 새로운 청크를 생성
랭체인에서 지원되는 스플리터로는 크게 CharacterTextSplitter, RecursiveCharacterTextSplitter가 있습니다. 랭체인 공식문서에 따르면 기본적으로 권장되는 텍스트 스플리터는 RecursiveCharacterTextSplitter 입니다. 해당 스플리터는 문자 목록을 기반으로 분리를 수행합니다. 문자 목록의 첫 문자를 기준으로 청크를 분리하고, 만약 청크 중, 크기가 큰 조각이 있을 경우, 다음 문자를 활용해서 분리를 수행하는 방식입니다. 이와 다르게 CharacterTextSplitter의 경우, 지정한 문자를 기준으로 분리를 수행합니다. 이에 따라 청크가 생성되는 과정에서 지정된 크기보다 큰 청크가 생성될 수 있습니다.
이번 포스팅에서는 랭체인 텍스트 스플리터와 Streamlit을 결합하여 실시간으로 스플리터 종류, 청크 사이즈, 오버랩 사이즈 등을 설정하는 기능을 구현할 것입니다. 또한, 설정된 조건에 따라 텍스트가 어떻게 나눠지는지 확인하면서 텍스트 스플리터에 대해 이해해보도록 하겠습니다.
Streamlit을 통해 실시간 입력 화면 구성하기
이전 포스팅에 이어서 오늘도 Streamlit을 활용해서 환경을 구성할 것입니다. 지난번에는 단순히 URL, API 키 등 텍스트 입력만 받았다면, 오늘은 슬라이드 바(slider), 선택 박스(selectbox)를 추가로 구현해서 설정 값을 입력받을 것입니다. 우선, 이번 예제에서 활용할 라이브러리인 streamlit, WebBaseLoader, RecursiveCharacterTextSplitter, CharacterTextSplitter를 불러오도록 하겠습니다.
import streamlit as st
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.text_splitter import CharacterTextSplitter
Streamlit 라이브러리를 활용해서 텍스트 입력, 슬라이드 바, 선택 박스를 아래와 같이 생성합니다. 입력 받는 항목으로 웹 페이지의 주소(텍스트 입력), 텍스트 스플리터 종류(선택 박스), 청크, 오버랩 사이즈(슬라이드 바) 입니다.
url = st.text_input("Insert the URL")
selected_splitter = st.selectbox('Select a splitter', ['RecursiveCharacterTextSplitter',
'CharacterTextSplitter'])
chunk_size = st.sidebar.slider('Chunk Size', 1, 5000, 1000)
chunk_overlap = st.sidebar.slider('Chunk Overlap', 0, chunk_size, 0)
st.divider()
LangChain Text Splitters를 통한 텍스트 나누기
앞선 내용에서 코드 몇 줄을 통해 입력 화면을 쉽게 구현했습니다. 이제 입력 받은 값을 활용해서 스플리터를 처리하는 코드를 구현해보도록 하겠습니다. 구현하는 코드는 아래 항목의 내용을 수행합니다.
- 웹 페이지의 주소가 입력되면 입력된 주소로부터 데이터를 로드합니다.
- 선택 박스를 통해 입력된 스플리터의 종류에 따라 텍스트 스플리터를 생성합니다.
- 생성된 스플리터의 split_documents() 함수를 활용해서 청크를 생성합니다.
- 생성된 청크를 순회하면서 각 청크의 길이 및 내용을 확인합니다.
if url:
# 웹 주소를 통해 데이터 로드
loader = WebBaseLoader(url)
data = loader.load()
# 선택 박스의 값에 따라 스플리터 생성
if (selected_splitter == 'RecursiveCharacterTextSplitter'):
st.header("RecursiveCharacterTextSplitter")
recursive_character_text_splitter = RecursiveCharacterTextSplitter(separators='\\n', chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# 텍스트 분리
docs = recursive_character_text_splitter.split_documents(data)
elif (selected_splitter == 'CharacterTextSplitter'):
st.header("CharacterTextSplitter")
character_text_splitter = CharacterTextSplitter(separator=' ', chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# 텍스트 분리
docs = character_text_splitter.split_documents(data)
# 생성 결과 출력
st.subheader(f"Created chunks: {len(docs)}")
st.subheader(f"Total content length: {len(data[0].page_content)}")
for doc in docs:
st.subheader(f"Content length: {len(doc.page_content)}")
st.write(doc.page_content)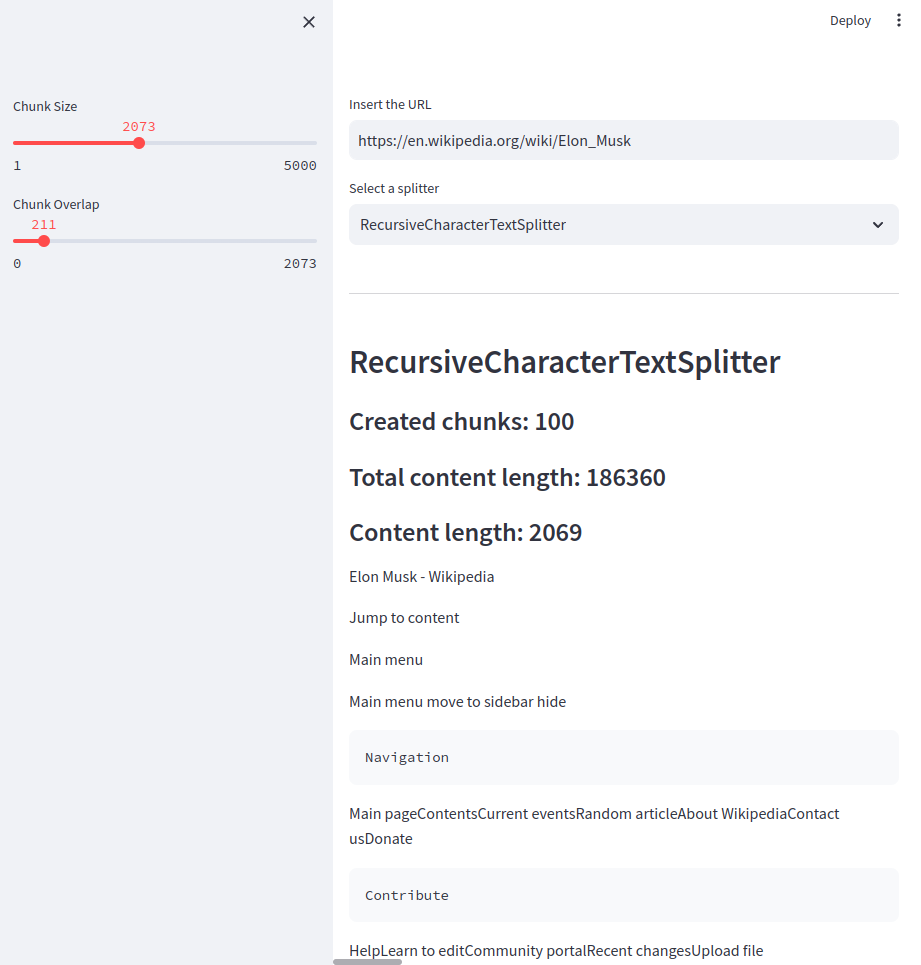
위의 결과를 보시면 설정된 값을 통해 생성된 청크의 개수, 기존 텍스트의 길이, 첫번째 생성된 청크의 텍스트 길이, 텍스트 내용이 아래 표시됩니다. 아래로 스크롤을 내려보시면 다음 청크의 길이, 텍스트 내용이 이어서 표시되는 것을 확인할 수 있습니다.
각 스플리터 별로 생성된 결과를 더 자세히 확인해보겠습니다. RecursiveCharacterTextSplitter를 통해 생성된 청크의 경우, 설정된 청크 사이즈를 초과하지 않으면서 사이즈에 근접한 청크를 생성합니다. 또한 설정한 오버랩 사이즈만큼 텍스트의 내용이 앞뒤로 중복되는 것을 확인할 수 있습니다.
CharacterTextSplitter는 정의된 seperator에 따라 분리됩니다. 이에 따라 텍스트가 seperator를 만나지 못할 경우, 텍스트가 원활하게 분리되지 않거나 생성된 청크의 사이즈가 클 수도 있습니다. 따라서, 사용하고자 하는 용도에 따라 스플리터 특성을 고려해서 선택하시면 될 것 같습니다.
마치며
오늘 포스팅에서는 랭체인에서 제공하는 텍스트 스플리터의 기능에 대해 알아보았습니다. 언어 모델 기반 애플리케이션을 개발할 때, 입력 데이터를 처리하는 과정은 매우 중요합니다. 특히, 보통 애플리케이션에서 다루는 텍스트의 양이 방대하기 때문에 이를 효과적으로 처리하는 과정이 필요합니다. 대용량의 텍스트 데이터에 포함되어 있는 의미 있는 정보를 언어 모델에 제대로 사용하기 위해서는 의미론적으로 연관된 텍스트를 적절히 분리하고 재조합하는 과정이 필요하고, 이는 모델의 성능 향상 뿐만 아니라 데이터를 해석하는 능력을 향상시킬 수 있습니다.
랭체인에서 제공하는 텍스트 스플리터는 언어 모델에 입력되는 텍스트를 유연하게 처리할 수 있도록 기능을 제공합니다. 텍스트의 내용과 구조를 최대한 보존하면서 사용자의 필요에 따라 청크의 크기나 형태를 조정할 수 있도록 합니다. 랭체인을 활용한 애플리케이션을 개발하는 과정에서 텍스트 스플리터의 기능을 활용함으로써 대용량 데이터를 효과적으로 활용할 수 있었으면 좋겠습니다. 오늘도 도움이 되셨기를 바라면서 포스팅 마치도록 하겠습니다. 감사합니다.
'Tech Insights' 카테고리의 다른 글
| 랭체인(LangChain)과 판다스(Pandas)를 결합한 데이터 분석 AI (0) | 2023.11.07 |
|---|---|
| 모바일 ChatGPT - Voice 기능을 활용한 영어 회화 연습하기 (0) | 2023.10.29 |
| 랭체인(LangChain) Callback을 활용한 실시간 토큰 사용량 확인하기 (0) | 2023.10.25 |
| 랭체인(Langchain), Streamlit을 활용해서 웹 기반 챗봇 만들기 (0) | 2023.10.19 |
| 임베드체인(Embedchain) - Easy 하게 LLM 플랫폼 개발하기 (1) | 2023.10.17 |



