
랭체인(LangChain)과 판다스(Pandas)를 결합한 데이터 분석 AI
목차
- Streamlit을 이용한 인터페이스 생성
- Pandas Agent 생성, 프롬프트 설정
- 예제 프로그램 사용 결과
- 마치며
안녕하세요. 오늘은 오랜만에 랭체인(LangChain)과 관련된 내용을 소개드리고자 합니다. 오늘 소개드릴 내용은 랭체인과 Pandas를 활용해서 CSV(Comma separated Values) 형식의 파일을 분석하는 내용입니다. 여기서, CSV 파일은 스프레드시트 프로그램(Microsoft Excel, Google Sheets)과 데이터베이스 관리 시스템에서 널리 사용되는 파일입니다. 쉼표로 분리된 텍스트 파일로써 테이블 데이터를 텍스트 형식으로 저장하는 데 용이합니다.
오늘 사용할 Pandas는 파이썬에서 데이터 분석, 데이터 전처리, 데이터 시각화 등에 널리 사용되는 오픈소스 라이브러리입니다. Pandas에서 제공하는 데이터프레임(DataFrame), 시리즈(Series), 데이터 후처리 기능, 파일 입출력, 시계열 분석 등의 기능이 강력하고 간편하게 사용할 수 있기 때문에 금융 데이터 분석, 경제학, 광고 데이터 분석 등 다양한 분야의 데이터 처리에 활용됩니다. Pandas에서 제공하는 풍부한 기능과 편리한 데이터 구조는 복잡한 데이터 작업을 단순화하고, 데이터 분석 작업을 더 빠르고 효율적으로 수행할 수 있도록 합니다.
오늘 소개드릴 포스팅에서는 이전 랭체인 시리즈에서 활용했던 Streamlit을 활용할 예정입니다. Streamlit을 활용해서 CSV 파일을 업로드, 사용자 쿼리를 전달할 수 있는 인터페이스를 구성할 것입니다. CSV로 전달된 데이터를 Pandas와 랭체인을 활용해서 처리하고 사용자가 요청한 쿼리에 대해 데이터 테이블, 차트, 그래프 가시화 역할을 수행할 것입니다. 랭체인에 대한 기본 소개와 Streamlit을 활용한 기능에 대한 내용을 참고하시자 할 경우, 참고하실 수 있도록 맨 아래에 링크를 남겨놓도록 하겠습니다.
Streamlit을 이용한 인터페이스 생성
CSV 데이터 분석을 수행하기 앞서 CSV 파일을 업로드하고 사용자 쿼리를 입력할 수 있는 인터페이스를 만들 것입니다. 추가로, 지난 시간 구성한 UI 외에 페이지 타이틀, 아이콘, 레이아웃 등을 설정해 보도록 하겠습니다. 우선, 오늘 예제에 필요한 라이브러리를 불러옵니다. 오늘 예제에서는 랭체인, Pandas, Streamlit 등의 라이브러리를 사용할 예정입니다.
from langchain import OpenAI
from langchain.agents import create_pandas_dataframe_agent
import json
import pandas as pd
import streamlit as st
오늘 Streamlit을 활용하면서 추가로 구현할 부분은 set_page_config() 함수를 사용한 페이지 설정입니다. 해당 함수를 사용하면 아래와 같이 페이지 타이틀, 아이콘, 레이아웃 등을 설정할 수 있습니다. 추가로, API 키 입력, CSV 파일 입력, 쿼리 입력 인터페이스를 아래와 같이 구현합니다.
# 페이지 설정
st.set_page_config(
page_title="👨💻 Talk with your CSV",
page_icon="📊",
layout="wide",
)
# 사용자 입력 인터페이스
api_key = st.text_input("Enter your OpenAI API Key", type="password")
file = st.file_uploader("Upload a CSV" , type="csv")
query = st.text_area("Send a Message")
위의 코드를 수행하면 아래의 그림과 같이 웹 페이지의 타이틀과 아이콘이 생성된 것을 확인할 수 있습니다. 또한 API 키, CSV 파일 업로드, 쿼리 메시지 입력 창이 생성되었습니다. 오늘 예제에서는 이전 포스팅과 동일하게 OpenAI의 LLM 모델을 사용할 예정입니다. 따라서, OpenAI에서 발급받은 API키가 필요합니다.

Pandas Agent 생성, 프롬프트 설정
CSV 파일을 분석하기 위해서 Pandas를 활용해서 데이터 프레임을 생성하고 랭체인의 Pandas 데이터 프레임 Agent를 사용할 것입니다. 또한, Agent의 응답을 원하는 형태로 획득하기 위해 프롬프트를 설정할 것입니다. 아래의 코드를 설명하면서 계속 진행해 보도록 하겠습니다. 우선, 사용자 인터페이스를 통해 전달된 CSV 파일을 데이터 프레임으로 변경합니다. 추가로, OpenAI 모델과 데이터 프레임을 활용해서 Pandas Agent를 생성합니다.
if st.button("Submit", type="primary"):
# Pandas DataFrame Agent 생성
df = pd.read_csv(file)
pd_agent = create_pandas_dataframe_agent(OpenAI(temperature=0,
openai_api_key=api_key),
df,
verbose=True,)
위의 코드에서 볼 수 있듯이 Submit 버튼을 클릭하면 입력된 CSV 파일을 read_csv() 함수를 통해 데이터 프레임으로 변경합니다. 또한 create_pandas_dataframe_agent() 함수를 통해 Pandas Agent를 생성합니다. 이후, Pandas Agent에 쿼리를 전달하고 응답을 획득할 것입니다.
이어서, 원하는 형태의 답변을 얻기 위해 프롬프트를 생성할 것입니다. 프롬프트에 요청사항을 작성하여 막대그래프, 선 그래프, 테이블, 일반 답변 등에 따라 정해진 형식에 맞춰 응답을 받도록 요청할 것입니다. 생성된 프롬프트에 사용자 쿼리를 추가하여 Pandas Agent에 전달하고 응답을 획득합니다. 또한 생성된 입력을 Json 포맷으로 변경합니다.
# 프롬프트 생성 및 Pandas Agent에 응답 요청
prompt = (
"""
The responses depend on the type of information requested in the query.
You should follow the instructions below to generate an answer.
1. If the query requires a table, format your answer like this:
{"table": {"columns": ["column1", "column2", ...], "data": [[value1, value2, ...], [value1, value2, ...], ...]}}
2. For a bar chart, respond like this:
{"bar": {"columns": ["A", "B", "C", ...], "data": [1, 2, 3, ...]}}
3. If a line chart is more appropriate, your reply should look like this:
{"line": {"columns": ["A", "B", "C", ...], "data": [1, 2, 3, ...]}}
4. For a plain question that doesn't need a chart or table, your response should be:
{"answer": "Your answer goes here"}
5. If the answer is not known or available, respond with:
{"answer": "I do not know."}
Return all output as a string.
Remember to encase all strings in the "columns" list and data list in double quotes.
For example: {"columns": ["Products", "Orders"], "data": [["ABC", 123], ["ABC", 123]]}
Now, let's tackle the query step by step.
Here's the query for you to work on:
"""
+ query
)
response = pd_agent.run(prompt)
response_dict = json.loads(response)
위의 프롬프트를 사용하면 요청하는 쿼리에 따라 아래 종류의 응답을 얻으실 수 있습니다. 이후, 획득한 응답에 따라 후처리를 진행하면 원하는 텍스트 응답이나 그래프, 테이블 데이터를 획득할 수 있습니다.
- 막대그래프: {"bar": {"columns": ["A", "B", "C", ...], "data": [25, 24, 10, ...]}}
- 선 그래프: {"line": {"columns": ["A", "B", "C", ...], "data": [25, 24, 10, ...]}}
- 테이블: {"table": {"columns": ["column1", "column2", ...], "data": [[value1, value2, ...], [value1, value2, ...], ...]}}
- 일반 응답: {"answer": "Your answer goes here"}
위의 응답에 대해 처리를 진행하기 위해 아래와 같이 코드를 구성합니다. 아래의 예제 코드는 사용하는 데이터 셋을 기준으로 작성한 코드입니다. 따라서, 일반적인 경우에 대해 적용되지 않을 수 있습니다. 아래의 코드를 보시면 위의 네 가지의 경우에 대해 조건을 나누어 처리를 진행합니다.
# 응답 출력
if "answer" in response_dict:
st.write("The answer is: ", response_dict["answer"])
elif "bar" in response_dict:
data = response_dict["bar"]
df = pd.DataFrame(data["data"], columns=data["columns"])
df.set_index("PassengerId", inplace=True)
st.bar_chart(df)
elif "line" in response_dict:
data = response_dict["line"]
df = pd.DataFrame(data["data"], columns=data["columns"])
df.set_index("PassengerId", inplace=True)
st.line_chart(df)
elif "table" in response_dict:
data = response_dict["table"]
df = pd.DataFrame(data["data"], columns=data["columns"])
st.table(df)
예제 코드에 대한 설명은 끝났습니다. 이제 예제 데이터를 입력하고 출력 결과가 어떻게 획득되는지 확인해 보도록 하겠습니다. 오늘 사용할 예제는 케글(Kaggle)에서 자주 사용되는 타이타닉 예제 파일을 사용할 예정입니다. 다만, 사용 토큰의 양을 고려하여 데이터 셋의 일부만 사용합니다. 예제 데이터를 사용하고자 하실 경우, 아래의 내용을 CSV 파일 형태로 저장하여 사용하시면 됩니다.
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",female,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",male,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",male,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",male,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",male,2,3,1,349909,21.075,,S
9,1,3,"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)",female,27,0,2,347742,11.1333,,S
10,1,2,"Nasser, Mrs. Nicholas (Adele Achem)",female,14,1,0,237736,30.0708,,C
11,1,3,"Sandstrom, Miss. Marguerite Rut",female,4,1,1,PP 9549,16.7,G6,S
12,1,1,"Bonnell, Miss. Elizabeth",female,58,0,0,113783,26.55,C103,S
13,0,3,"Saundercock, Mr. William Henry",male,20,0,0,A/5. 2151,8.05,,S
14,0,3,"Andersson, Mr. Anders Johan",male,39,1,5,347082,31.275,,S
15,0,3,"Vestrom, Miss. Hulda Amanda Adolfina",female,14,0,0,350406,7.8542,,S
16,1,2,"Hewlett, Mrs. (Mary D Kingcome) ",female,55,0,0,248706,16,,S
17,0,3,"Rice, Master. Eugene",male,2,4,1,382652,29.125,,Q
18,1,2,"Williams, Mr. Charles Eugene",male,,0,0,244373,13,,S
19,0,3,"Vander Planke, Mrs. Julius (Emelia Maria Vandemoortele)",female,31,1,0,345763,18,,S
20,1,3,"Masselmani, Mrs. Fatima",female,,0,0,2649,7.225,,C
21,0,2,"Fynney, Mr. Joseph J",male,35,0,0,239865,26,,S
22,1,2,"Beesley, Mr. Lawrence",male,34,0,0,248698,13,D56,S
23,1,3,"McGowan, Miss. Anna ""Annie""",female,15,0,0,330923,8.0292,,Q
24,1,1,"Sloper, Mr. William Thompson",male,28,0,0,113788,35.5,A6,S
25,0,3,"Palsson, Miss. Torborg Danira",female,8,3,1,349909,21.075,,S
예제 프로그램 사용 결과
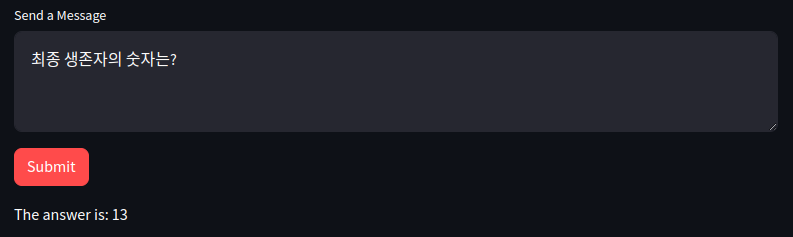
1. 일반 응답
CSV 데이터에서 '최종 생존자의 숫자는?'을 물어봤을 때, ' Survived' 데이터를 참고하여 최종 생존자의 숫자를 정확하게 답변하는 것을 확인할 수 있습니다.
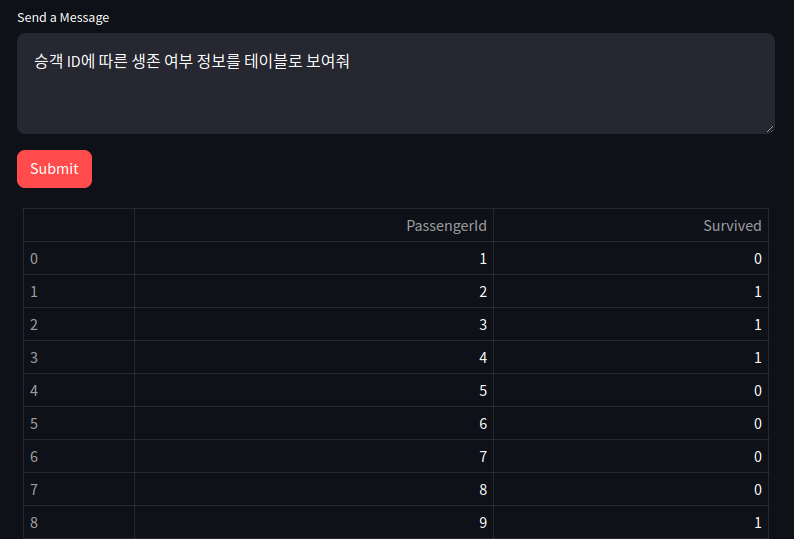
2. 테이블 응답
CSV 데이터에서 '승객 ID에 따른 생존 여부 정보를 테이블로 보여줘'를 요청했을 때, 아래의 그림과 같이 테이블을 생성해 주는 것을 확인할 수 있습니다.
3. 막대그래프
CSV 데이터에서 'x축 PassengerId, y축 요금 정보에 대해 막대그래프로 보여줘'의 쿼리에 대해 아래와 같이 막대그래프로 결과가 나타나는 것을 확인할 수 있습니다.

4. 선 그래프
CSV 데이터에서 'x축 PassengerId, y축 요금 정보에 대해 선 그래프로 보여줘'의 쿼리에 대해 아래와 같이 막대그래프로 결과가 나타나는 것을 확인할 수 있습니다.

마치며
오늘은 랭체인과 Pandas 라이브러리를 활용해서 CSV를 분석하는 것을 진행했습니다. Streamlit을 통해 CSV 파일과 쿼리를 입력받아 랭체인의 Pandas Agent를 통해 응답을 생성하는 것을 진행했습니다. 정해진 형식을 지키는 응답을 얻기 위해 프롬프트를 활용하여 형식에 대한 Agent에 전달했습니다. 예제 결과, 쿼리의 요청에 따라 텍스트, 테이블, 그래프 응답을 얻을 수 있었습니다.
금일 보여드린 예제의 경우, 특정 데이터 셋에서 동작하도록 작성되었기 때문에 일반적인 경우에 모두 적용되지는 않습니다. 하지만, 원하는 상황에 따라 코드를 작성한다면 랭체인과 Pandas를 적절하게 조합해서 사용할 수 있을 것으로 생각됩니다. ChatGPT의 기능과 Pandas의 데이터 분석 및 처리 기능을 조합해서 사용하면 각 플랫폼의 시너지 효과를 얻을 수 있을 것입니다. 추후, 기회가 된다면 Pandas에서 제공하는 PandasAI에 대해서도 다룰 수 있도록 하겠습니다.
오늘도 포스팅을 읽어주셔서 감사합니다. 도움이 되셨기를 바라면서 다음에 더 좋은 글로 찾아뵐 수 있도록 하겠습니다.
이전 참고 글
LangChain - 초보자를 위한 완벽 가이드
LangChain - 초보자를 위한 완벽 가이드 목차 폭발적으로 증가하는 LLM 플랫폼 그래서 랭체인은 무엇일까? 랭체인의 주요 모듈 랭체인 실습 예제 마치며 폭발적으로 증가하는 LLM 플랫폼 안녕하세요.
kudositdaily.tistory.com
랭체인(Langchain), Streamlit을 활용해서 웹 기반 챗봇 만들기
랭체인(Langchain), Streamlit을 활용해서 웹 기반 챗봇 만들기
랭체인(Langchain), Streamlit을 활용해서 웹 기반 챗봇 만들기 목차 Streamlit 간단 예제 랭체인, Streamlit을 활용한 웹 애플리케이션 만들기 마치며 안녕하세요. 오늘도 랭체인과 관련한 내용을 소개드리
kudositdaily.tistory.com
'Tech Insights' 카테고리의 다른 글
| OpenAI DevDay 2023 - ChatGPT의 혁신적인 신규 기능 소개 (2) | 2023.11.14 |
|---|---|
| 구글 바드(Bard)와 구글 서비스를 통합해서 생산성 향상시키기 (0) | 2023.11.12 |
| 모바일 ChatGPT - Voice 기능을 활용한 영어 회화 연습하기 (0) | 2023.10.29 |
| 랭체인(LangChain), Streamlit을 활용한 실시간 텍스트 나누기 (0) | 2023.10.26 |
| 랭체인(LangChain) Callback을 활용한 실시간 토큰 사용량 확인하기 (0) | 2023.10.25 |



