랭체인(Langchain) Callback을 활용한 실시간 토큰 사용량 확인하기

목차
- Introduction
- 랭체인 Callback 기능을 활용해서 토큰 사용량 확인하기
- 마치며
Introduction
안녕하세요. 지난 포스팅에 이어 이번 포스팅에서도 랭체인 관련 내용을 다루고자 합니다. 언어모델을 활용한 애플리케이션을 개발하다 보면 '토큰(Token)'이라는 용어를 자주 접하게 됩니다. 토큰은 주어진 텍스트를 처리할 수 있는 작은 단위로, 주로 단어, 문자, 혹은 부분 문자열(substring)을 의미합니다. 언어 모델에서 토큰은 텍스트를 처리하는 기본 단위가 되는데요. GPT와 같은 언어 모델은 주어진 텍스트를 토큰 단위로 나눈 뒤, 각 토큰을 임베딩 벡터(embedding vector)로 변환하여 모델의 입력으로 사용합니다.
보통 저희가 사용하는 언어모델은 한 번에 처리할 수 있는 토큰의 수에 제한이 있습니다. OpenAI의 API 또한 정해진 시간에 요청할 수 있는 횟수가 제한되어 있습니다. 이렇게 API를 활용하는 데 제한을 두는 이유는 몇 가지가 있습니다.
- API의 오남용 방지
- API 사용의 공정성 유지
- 서버 인프라에 대한 부하(load) 관리
OpenAI에서는 사용량을 RPM(Requests Per Minute), RPD(Requests Per Day), TPM(Tokens Per Minute)의 형태로 측정하고 있고, 사용량에 따라 요금을 부과합니다. 따라서, 언어 모델 사용자는 현재 내가 얼마만큼의 토큰을 사용하고 있는지 파악하는 것이 중요합니다. 토큰 사용량을 실시간으로 파악함으로써 사용 요금에 대해 파악할 수 있고, 언어 모델의 제한 토큰을 고려함으로써 대용량 문서나 프롬프트를 효과적으로 다룰 수 있기 때문입니다.
오늘은 랭체인을 사용하여 개발하는 과정에서 콜백(Callback) 기능을 활용하는 방법에 대해 소개하고자 합니다. 랭체인의 콜백을 활용할 경우, 언어모델이 동작하는 과정에서 발생하는 이벤트를 용이하게 처리할 수 있습니다. 오늘은 그중에서 실시간으로 토큰의 사용량을 확인하는 방법에 대해 안내해 드리도록 하겠습니다.
랭체인 Callback 기능을 활용해서 토큰 사용량 확인하기
오늘 다룰 예제는 지난 랭체인(Langchain), Streamlit을 활용해서 웹 기반 챗봇 만들기에서 다뤘던 예제를 활용해 보도록 하겠습니다. 지난 예제에서는 Streamlit을 활용해서 웹에서 운용되는 챗봇을 구현했습니다. 챗봇에게 웹 페이지 링크를 전달하고 웹 페이지의 내용을 참조해서 대화할 수 있도록 했습니다. 해당 예제에 토큰 사용량을 확인할 수 있는 기능을 추가하고자 합니다.
오늘 사용하고자 하는 라이브러리는 랭체인의 callbacks이고, get_openai_callback() 함수를 사용할 예정입니다. 따라서, 아래와 같이 함수를 임포트 합니다.
from langchain.callbacks import get_openai_callback
함수를 불러온 후, 해당 함수를 활용해서 언어모델에 쿼리를 보내는 구간을 아래와 같이 감싸줍니다. 콜백으로 감싸준 후, 예제 코드를 실행하면 아래의 그림과 같은 결과가 출력됩니다. 결과의 아래 부분을 보시면, 사용된 토큰, 사용 요금 등이 표시됩니다.
with get_openai_callback() as cb:
result = qa(query)
st.write(result)
st.write(cb)
만약 Callback 되는 객체의 멤버에 개별적으로 접근하고자 할 경우, 아래와 같이 확인할 수 있습니다. 해당 코드를 적용하면 아래와 같은 결과를 얻으실 수 있습니다.
with get_openai_callback() as cb:
result = qa(query)
st.write(result)
st.write(f"Total cost is {cb.total_cost}")
st.write(f"Total tokens is {cb.total_tokens}")
st.write(f"Successfult requests is {cb.successful_requests}")
st.write(f"Prompt tokens is {cb.prompt_tokens}")
st.write(f"Completion tokens is {cb.completion_tokens}")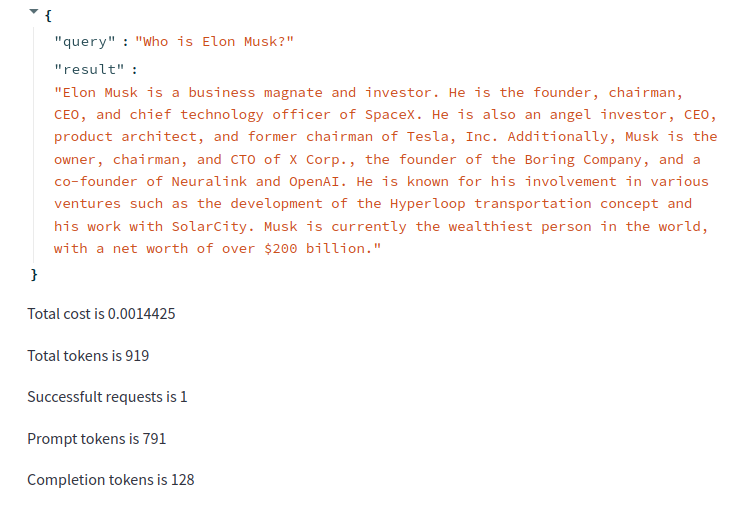
예제에 대한 전체 코드를 참조하고자 하실 경우, 아래를 확인해 주시기 바랍니다.
import os
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.callbacks import get_openai_callback
__import__('pysqlite3')
import sys
sys.modules['sqlite3'] = sys.modules.pop('pysqlite3')
ABS_PATH: str = os.path.dirname(os.path.abspath(__file__))
DB_DIR: str = os.path.join(ABS_PATH, "database")
# Title
st.title("Talk with your Website")
# Inputs
key = st.text_input("Enter your OPEN_API_KEY")
url = st.text_input("Insert the URL")
query = st.text_input("Send a Message")
if st.button("Submit", type="primary"):
# Load data from URL
loader = WebBaseLoader(url)
data = loader.load()
# Split the loaded data
text_splitter = CharacterTextSplitter(separator='\\n', chunk_size=1000,chunk_overlap=200)
docs = text_splitter.split_documents(data)
# Create Language Model
openai_llm = ChatOpenAI(openai_api_key=key)
# Create embeddings
openai_embeddings = OpenAIEmbeddings(openai_api_key=key)
# Create vector database
vector_database = Chroma.from_documents(documents=docs, embedding=openai_embeddings, persist_directory=DB_DIR)
vector_database.persist()
# Create a retriever from Chroma db
retriever = vector_database.as_retriever(search_kwargs={"k":3})
# Chain
qa = RetrievalQA.from_chain_type(llm=openai_llm, chain_type="stuff", retriever=retriever)
# Callback
with get_openai_callback() as cb:
result = qa(query)
st.write(result)
st.write(cb)
# st.write(f"Total cost is {cb.total_cost}")
# st.write(f"Total tokens is {cb.total_tokens}")
# st.write(f"Successfult requests is {cb.successful_requests}")
# st.write(f"Prompt tokens is {cb.prompt_tokens}")
# st.write(f"Completion tokens is {cb.completion_tokens}")
마치며
언어 모델을 활용한 애플리케이션을 개발할 때, 토큰을 제대로 관리하는 것은 상당히 중요합니다. 토큰은 언어 모델 API를 사용하는 과정에서 핵심 요소입니다. 토큰을 제대로 관리하는 것은 단순히 사용 비용 문제를 넘어 애플리케이션의 전반적인 성능과 효율성에 큰 영향을 미칩니다. 개발자는 애플리케이션에서 언어 모델의 사용량을 제대로 파악하고, 이를 통해 제품의 비용을 관리하거나 성능 최적화, 사용자 경험 향상 등의 작업을 수행합니다.
랭체인에서 제공하는 콜백 기능은 몇 줄의 코드를 작성하는 것만으로도 토큰 사용량, 요금 정보 등을 실시간으로 파악할 수 있습니다. 이는 리소스를 효과적으로 관리하고, 예상치 못한 비용이 발생하는 것을 방지해 줍니다. 오늘 소개해드린 기능 외에 랭체인에서 제공하는 여러 개발 기능을 적절히 활용하면 효과적인 애플리케이션 개발에 도움이 될 것이라 생각합니다.
오늘 포스팅은 여기서 마치면서 더 좋은 내용으로 찾아뵐 수 있도록 노력하겠습니다. 감사합니다.
'Tech Insights' 카테고리의 다른 글
| 모바일 ChatGPT - Voice 기능을 활용한 영어 회화 연습하기 (0) | 2023.10.29 |
|---|---|
| 랭체인(LangChain), Streamlit을 활용한 실시간 텍스트 나누기 (0) | 2023.10.26 |
| 랭체인(Langchain), Streamlit을 활용해서 웹 기반 챗봇 만들기 (0) | 2023.10.19 |
| 임베드체인(Embedchain) - Easy 하게 LLM 플랫폼 개발하기 (1) | 2023.10.17 |
| DALL-E 3 - ChatGPT의 혁신적인 이미지 생성 AI (0) | 2023.10.15 |



